







Наш великий и могучий русский язык не только красив, но и очень сложен. Зачастую даже интуитивное представление носителей языка идет вразрез с формальным. Результаты машинного разбора еще разительнее отличаются от нашего интуитивного представления.
В этой статье мы разберем, как поисковые системы понимают запросы пользователя, находят соответствующие документы и как из запроса извлекается его семантическое значение.

Казалось, прежде чем Google представил RankBrain, а Яндекс - Королев, SEO продвижение и жизнь SEO специалистов были намного проще. Теперь мы подвержены потоку противоречивой информации от влиятельных лиц отрасли. Ситуация усугубляется тем, что представители Яндекс и Google дают малопонятную информацию о качественных сигналах и в голос твердят одно и то же: «Делайте сайты для людей».
Как отличить бесполезные советы и предположения о работе алгоритмов от реальных действующих методов? Ниже вы найдете ответы на вопросы, которые помогут понять, как устроены поисковые системы и суть работы SEO оптимизатора. Читайте и становитесь настоящим гуру поисковой оптимизации...
Слово для поисковой системы
Слово — это самая маленькая смысловая единица речи, которая служит для выражения отдельного понятия. Для начала выясним, как слова представлены в компьютерных программах, и выявим сильные и слабые стороны данных подходов.
В простейшем случае компьютерная программа видит текст как последовательность буквенно-цифровых символов и знаков препинания. Это так называемое необработанное представление текста.
| «Программы программиста были запрограммированы». |
Некоторые слова могут быть разделены пробелами или пунктуацией. В результате мы получаем список символов. Знаки препинания рассматриваются тоже как отдельные символы.
Стоит отметить такую особенность любого текста как заглавные буквы. Кажется разумным заменить все символы на нижний регистр. В конце концов, «Какой» и «какой» представляют собой одно и то же слово, а именно местоимение. Но как насчет слова «вера» и имени «Вера», которое в зависимости от контекста может быть именем собственным или нарицательным.
Необработанные символы сохраняют всю лингвистическую информацию, но в то же время возникает больше вопросов при вводе. Дальнейшая пост-обработка проводится для избавления от лишней информации.
| Программы программиста были запрограммированы. |
Слова могут иметь разные формы. Например, слово «программы» является формой существительного множественного числа от «программа». «Запрограммированный» - это причастие прошедшего времени, образованное от глагола «программировать». Неизмененная, исходная форма слова называется лемма. Для существительных это именительный падеж и единственное число, для глаголов — форма слова, отвечающая на вопрос «что делать?» Первый логический шаг в обработке запроса – преобразовать слова в их соответствующие леммы.
| Программа программиста должна быть программной. |
Поисковые системы используют стоп-слова для предварительной обработки вводимых запросов. Список стоп-слов – это набор символов, которые удаляются из текста. Стоп-слова могут включать функциональные слова и знаки препинания. Функциональные слова - это слова, которые не имеют самостоятельного значения, например, вспомогательные глаголы или местоимения.
Для примера попробуем отбросить функциональные слова из предложения. В результате исходное высказывание содержит только содержательные слова (слова, имеющие смысловое значение). Однако сложно сказать, как программа в запросе связана с программистом.
| программист программа программа |
Также поисковые системы могут понимать слова, исходя из их оснований, то есть корней. Корень слова - это его главная значимая часть, в которой заключено общее значение всех однокоренных слов. Например, мы можем добавить суффикс «-ист» к основному корню «программ» и получим кого-то, кто выполняет действие.
Теперь посмотрим на преобразованный запрос при замене всех слов на их леммы.
| программа программа программа |
После сокращения изначального запроса мы получили, казалось бы, не очень информативную последовательность.
Существует три способа представления слов:
- символ;
- лемма;
- корень.
Кроме того, мы можем удалить все функциональные слова и преобразовать оставшиеся в нижний регистр. Такие обработки и их комбинации используются в зависимости от языка поставленной задачи. Например, будет нецелесообразно сокращать функциональные слова, если нам нужно дифференцировать тексты на английском и французском языках. А если же при запросе мы имели в виду именно собственное имя существительного, то разумно будет сохранить исходный регистр символов.
Эти лингвистические составляющие являются строительными блоками для более крупных структур, таких как документы.

Что нужно знать SEO-специалисту
- Важно понимать, зачем необходимо разбивать предложения на лингвистические составляющие. Эти единицы являются частью метрики, которую знают и используют оптимизаторы. Они составляют такой показатель, как плотность ключевых слов. Хотя многие SEO-оптимизаторы выступают против этого показателя и утверждают, что плотность ключевых слов ни на что не влияет. В качестве альтернативы они предлагают использовать показатель TF-IDF, поскольку он связан с семантическим поиском. Далее мы увидим, что как необработанные, так и взвешенные количества слов могут использоваться и для лексического и для семантического поисков.
- Плотность ключевых слов - это удобная и простая метрика, которая имеет право на существование. Однако не стоит зацикливаться на ней.
- Также имейте ввиду, что грамматические формы рассматриваются поисковыми системами как один и тот же тип слова, поэтому не имеет смысла оптимизировать веб-страницу, например, для единственного и множественного числа одного ключевого слова.

Мешок слов
 Мешок слов (bag-of-words) – это модель, которая используется при обработке естественного языка для представления текста (от поискового запроса до полномасштабной книги). Хотя эта концепция восходит к 1950-м годам, она все еще используется для классификации текста и поиска информации.
Мешок слов (bag-of-words) – это модель, которая используется при обработке естественного языка для представления текста (от поискового запроса до полномасштабной книги). Хотя эта концепция восходит к 1950-м годам, она все еще используется для классификации текста и поиска информации.
Если мы хотим представить текст как большой набор слов, т.е. «мешок слов», мы просто посчитаем, сколько раз каждое отдельное слово появляется в тексте, и перечислим эти значения. В математике это называется вектор. Перед подсчетом можно применить методы предварительной обработки, описанные в выше.
В результате теряется вся информация о текстовой структуре, синтаксисе и грамматике текста.
| программы программиста были запрограммированы {: 1, программист: 1, s: 1, программы: 1, имели: 1, были: 1, запрограммированы: 1} или [1, 1, 1, 1, 1, 1, 1] programmer program program {программист: 1, программа: 2} или [1, 2] |
Представлять отдельный текст в виде списка цифр практически нет смысла. Однако, если у нас есть список документов (например, все веб-страницы, проиндексированные определенной поисковой системой), мы можем построить так называемую векторную модель из доступных текстов.
Звучит пугающе, но на самом деле все просто. Представьте себе электронную таблицу, в которой каждый столбец представляет собой набор слов (вектор текста), а каждая строка представляет слово из набора этих текстов (вектор слова). Количество столбцов равно количеству документов в списке. Количество строк равно количеству уникальных слов, которые встречаются во всем списке документов.
Значение в пересечении каждой строки и столбца - это количество раз, когда соответствующее слово появляется в соответствующем тексте. В таблице ниже изображена векторная модель для пьес Шекспира. Для простоты восприятия мы используем всего четыре слова.
| Как вам это понравится | Двенадцатая ночь, или Что угодно | Юлий Цезарь | Генрих V | |
|---|---|---|---|---|
| Битва | 1 | 0 | 7 | 13 |
| Отличный | 114 | 80 | 62 | 89 |
| Дурачить | 36 | 58 | 1 | 4 |
| Остроумие | 20 | 15 | 2 | 3 |
Как мы уже говорили ранее, мешок слов на самом деле является вектором. Преимущество векторов в том, что мы можем измерить расстояние или угол между ними. Чем меньше расстояние или угол - тем больше «похожих» векторов и документов, которым они соответствуют. Это осуществляется с помощью показателя косинусного сходства. Результат варьируется от 0 до 1. Чем выше значение, тем больше похожих документов.
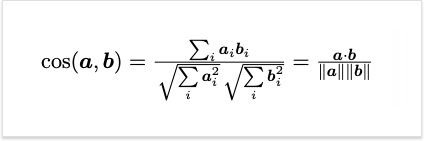
Поиск соответствующего документа
Допустим, пользователь вводит запрос «битва при Азенкуре». Это небольшой документ, который может быть встроен в векторное пространство, как в примере выше. Соответствующий вектор равен [1, 0, 0, 0]. «Отличный», «дурачить» и «остроумие» имеют нулевое число. Затем мы можем вычислить сходство поискового запроса с каждым документом в списке. Результаты приведены в таблице ниже. Видно, что Генрих V лучше всего соответствует запросу. Это неудивительно, поскольку слово «битва» встречается в этом тексте чаще. Этот документ можно считать более релевантным запросу. Также совсем необязательно, чтобы все слова в поисковом запросе присутствовали в тексте.
| Пьеса | Сходство |
|---|---|
| Как вам это понравится | 0,008249825 |
| Двенадцатая ночь, или Что угодно | 0 |
| Юлий Цезарь | 0.11211846 |
| Генрих V | 0,144310885 |
У такого подхода есть несколько очевидных недостатков:
- Уязвимый показатель плотности ключевых слов. Можно существенно повысить релевантность документа поисковому запросу, просто повторяя требуемое слово столько раз, сколько необходимо, чтобы превзойти конкурирующие документы в коллекции. Именно так работали поисковые системы на старте, в конце 1990-х. Достаточно было перенасытить текст ключевыми словами и первое место в выдаче гарантированно.
- Подбор документов для мешков слов типа
Меня впечатлило, это было неплохо! и
Я не был впечатлен, это было плохо! будет абсолютно одинаковым, хотя они имеют разные значения. Помните, что модель мешка слов не различает всю структуру, лежащую в основе документа. - Модель мешка слов с частотой встречаемости слова - не лучшая мера. Результаты поиска искажаются документами с высокой плотностью вводимых ключевых слов, хотя по факту эти документы могут не содержать нужной в себе информации.
В следующей части статьи мы подробно рассмотрим пункты:
- Проверка по закону Ципфа и метод TF-IDF.
- Как осуществляется семантический поиск.






